前段时间在工作中遇到php8+sg13的情况,于是花了点时间研究了下几种常见的加密与还原方法
文中提到的环境都更新在了 https://github.com/sco4x0/php-decrypt-env
无扩展加密
这种程度的加密,只是对代码本身做了压缩与编码,处理完之后本身就是一个正常可运行的文件,依托于php的变量与函数可以使用绝大部分字符(除了一些特字符),导致这种方式处理之后的文件内容几乎全是不可见字符,只有零星一些明显被编码后的字符串以及极个别函数符号可见。
由于加密强度不高,所以我们可以通过强行阅读处理后的文件来还原出解码方式从而获取原始代码,下面使用两种市面上常用的加密来做例子演示如何进行逆向还原
phpjm.net
工具使用地址:http://www.phpjm.net/
使用这种方式处理后的文件,只能运行在php<7的版本上,而且处理后的文件代码量较少,我们甚至可以直接通过手工的方式来对其进行还原,下面是一段代码被处理之后的情况
可以看到基本上全是不可见字符+编码后的字符串,其中可以注意到有一个明文可见的符号 base64_decode,所以也能确定那一堆可见字符就是一堆base64编码(低版本php在遇到非码表内的字符会进行忽略从而完成正常解析,而高版本php>=7会直接抛出异常,这也就是为什么这种处理后的代码只能跑在低版本php上),那么直接对代码进行一下格式化,然后尝试对其还原,格式化后的代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| <?php
/*
������������Ϣ�����DZ�php�ļ������ߣ����Ա��ļ�����������Ϣֻ���ṩ�˶Ա�php�ļ����ܡ������Ҫ��PHP�ļ����м��ܣ��밴������Ϣ��ϵ��
Warning: do not modify this file, otherwise may cause the program to run.
QQ: 1833596
Website: http://www.phpjm.net/
Copyright (c) 2012-2024 phpjm.net All Rights Reserved.
*/
if (!defined("EBCCDDCDEF")) {
define("EBCCDDCDEF", __FILE__);
global $�,$��,$���,$����,$����,$������,$�������,$��������,$���������,$����������,$�����������,$�����������,$�������������,$��������������,$���������������,$���������������;
function ��($��,$���="") {
global $�,$��,$���,$����,$����,$������,$�������,$��������,$���������,$����������,$�����������,$�����������,$�������������,$��������������,$���������������,$���������������;
if(empty($���)) {
return base64_decode($��);
} else {
return ��($�����������($��,$���,$���($���)));
}
}
$���=��("c3RycmV2�");
$�����������=��("c3RydHI=�");
$����=��("LXLhbA==�","ZpomPWJL");
$����=��("A3p1bmNvbXByAXNz�","ZTQA");
$������=��("nmFzZTn0X2R�ln29kZQ==�","YhJpAn");
$����������=��("SHJlZ19yZXBsYWNl�","chtS");
$���������������=��("ZzdlNWM5Yjd�iMDRhNjLlNT�JhMDm0LGVkM�zlhMjM5YjYz�Z2U=�","LomFgvZ");
function ����(&$����) {
global $�,$��,$���,$����,$����,$������,$�������,$��������,$���������,$����������,$�����������,$�����������,$�������������,$��������������,$���������������,$���������������;
$����������������=��("Okll�","ZGfMkO");
@$����������($���������������,$����."(@$����($������('eNptku1P2lAYxf8V�0vDhNuuUUosj5GZb�M0GJI4AghW0hLbQM�bGcFgsNpEFaohDfp�ECvC1j91vZeXGLaP�957fc87Nea57Aic2�IDRVqWixSEZSk9Ag�KCKT42MHGkEG3Hof�AwktUhGZiDJBoipr�CaT9enq+n08tDJyc�h5V0KgZNBJyHOOnb�CUIW5tB8fO4YmEny�Xy/FkP8sGYPwDnHS�RbWcRNidOWqbzU53�iDk5FaPnji5GPx4p�5YKMiGZjaLZvHwa9�n7MWhgqq/7KQ2oMt�ZHR4XOWUAuL6t/ez�32Zz2m63zWUqx5wW�OSZeXzhgrva9UApp�CQ6hxmDe0i1dN6xe�d/CE2eBhVMnQ/mp6�XouXhPcQjtFQuMZH�g2jioTtrdRZGo9U3�5ta4a+KZcIqV07xQ�T/NncOTgwoeL0yu1�FEYDExtms8Gj44Ns�NlCUwVYkIHbBzqu3�5GewS1AOSzlt2yT5�w90zFn9siE6f6C+B�G0mpSJvLiR24cfdm�1lSfOqeXtYAlQrmI�sojCx43Hnu4wqzWB�9ZQTtUJJvOCNsF0f�WFlQrxmahHBb3CwN�bCv/d/E4Pl5yh/Dv�e/dzPokVPX5vjmXl�vEDnmbyPFd74WNqz�JxAUQ5I403V97fqn�dBugrzfq2/Dd0nn9�foBvyZffyYbVoiqB�dRl4XwoTp0U1UhN5�rt5X+MgV2nEmnghp�itPaX0ZAL+E=�')));","���
������7e5c9b7b04a66e52a084ded39a239b63������");
return "�";
}
} else {
global $�,$��,$���,$����,$����,$������,$�������,$��������,$���������,$����������,$�����������,$�����������,$�������������,$��������������,$���������������,$���������������;
$���=��("c3RycmV2�");
$�����������=��("c3RydHI=�");
$����=��("LXLhbA==�","ZpomPWJL");
$����=��("A3p1bmNvbXByAXNz�","ZTQA");
$������=��("nmFzZTn0X2R�ln29kZQ==�","YhJpAn");
$����������=��("SHJlZ19yZXBsYWNl�","chtS");
$���������������=��("ZzdlNWM5Yjd�iMDRhNjLlNT�JhMDm0LGVkM�zlhMjM5YjYz�Z2U=�","LomFgvZ");
}
$���������=��("JU5vAjBNNE5CJ0F�DY4JxRWOZ�","ZxqeLAgnJ");
$��������=����($���������);
@$����������($���������������,$����."(@$����($������('eNo1jkEKwjAURK8�i8hcK8QSKnsVFwY�0iVBeu2sSkMaZp7�beNaZrqVY0LNwMz�bxhmuVmvNsfdcZJ�e0lOyn03Ph+".$���������.$��������."y20/nyj86HNDnNo�CXASwLPOoqW44dA�k700j8Y7y20k/fA�I1hEYscLXUEgCN6�wF0kJVBEp7E8aMt�IgFZLXO6dB6GwjQ�rEKRd0ZfPYu1/OH�fSK0QAuOANIFxx7�l0WpmeQNe07tOpv�g3hTmkTA+VZMcqM�lTK4RuHv9hfB0F7�u�')));","��
������7e5c9b7b04a66e52a084ded39a239b63�����");
return true;
?>cc7f01b3f642b179356e745ca3eef0b7
|
代码量不多,逻辑也比较清晰,如果觉得这类不可见字符影响阅读,甚至可以直接使用winhex等工具直接批量替换一下,首先可以看到这里面只有两个函数,将其重新命名为func0和func1,先来看看其中有符号 base64_decode 的func0,忽略掉那一堆扰乱视线的全局变量,将编码后的明文字符串带入,可以还原出func0函数的处理流程
1
2
3
4
5
6
7
8
9
| function func0($var1, $var2="") {
// global $varxxx...
if (empty($var2)) {
return base64_decode($var1);
} else {
//func0($varx($var1, $var2, $vary($var2)));
func0(strtr($var, $var2, strrev($var2)));
}
}
|
注释中的 varx 和 vary 其实就是 func0('c3RycmV2�') = strrev 以及 func0('c3RydHI=�') = strtr,到此最核心的解码函数其实就已经恢复完了,下面这一堆看起来很复杂的调用,其实就是解码需要用的函数符号,解码后的结果如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| $���=��("c3RycmV2�");
$�����������=��("c3RydHI=�");
$����=��("LXLhbA==�","ZpomPWJL");
$����=��("A3p1bmNvbXByAXNz�","ZTQA");
$������=��("nmFzZTn0X2R�ln29kZQ==�","YhJpAn");
$����������=��("SHJlZ19yZXBsYWNl�","chtS");
$���������������=��("ZzdlNWM5Yjd�iMDRhNjLlNT�JhMDm0LGVkM�zlhMjM5YjYz�Z2U=�","LomFgvZ");
/*
string(6) "strrev"
string(5) "strtr"
string(4) "eval"
string(12) "gzuncompress"
string(13) "base64_decode"
string(12) "preg_replace"
string(35) "/7e5c9b7b04a66e52a084ded39a239b63/e"
*/
|
以此类推,将所有不可见字符全都给替换回来之后,整个文件的代码就会变成如下所示,阅读起来非常简单
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| function func0($var1,$var2="") {
if(empty($var2)) {
return base64_decode($var1);
} else {
return func0(strtr($var1, $var2, strrev($var2)));
}
}
function func1(&$var1) {
eval(gzuncompress(base64_decode('xxxx')));
return pack('H*', '80');
}
$tmp_var = func0(pack('H*', '4A553576416A424E4E4535434A30469F4459344A7852574F5A83'), pack('H*', '5A7871654C41676E4A'));
$tmp_var2 = func1($tmp_var);
@preg_replace('/7e5c9b7b04a66e52a084ded39a239b63/e', "eval(@gzuncompress(base64_decode(str . $tmp_var . $tmp_var2 . str)));", '������7e5c9b7b04a66e52a084ded39a239b63�����');
|
在func1中还有一段 eval(gzuncompress(base64_decode('xxx'))) 的调用,将其进行恢复一下之后,发现是一段比较长的代码,除了一句对 $var1 进行赋值的代码,对还原文件没有什么太大的帮助,主要是对当前文件做一些md5的完整性校验等,赋值代码原型如下
1
| $var1 = gzuncompress(base64_decode($var1));
|
对其进行原样调用后就得到了 $tmp_var 以及 $tmp_var2 的值,将其进行拼接,然后做 gzuncompress(base64_decode) ,就可以还原出php本来的代码了
phpjiami.com
工具使用地址:https://www.phpjiami.com/phpjiami.html
经过这种方式处理后的代码,和 phpjm 没有什么本质上的区别,无非就是逻辑变得更复杂了一些,处理前后的代码对比如下所示
接下来介绍针对这种加密方式的还原方式
0x01 php dump
最早见于 @phith0n 在pwnhub公开赛中的writeup,个人感觉是比较惊艳的一种解法,原理是使用这种方式处理的文件在进行自解码后,会将结果存到变量中,使用这种方法可以通过查看变量的值来获取到初始代码
1
2
| include 'phpjiami.php';
var_dump(get_defined_vars());
|

但是如果代码中在一开始就写了这么点东西,这种方式就不适用了,因为整个流程在一开始就断掉,也就不存在走到var_dump了
1
2
3
4
5
| <?php
if (!isset($_SESSION['user'])) {
die('login first');
}
// ...
|
0x02 手工分析
这个代码量相比较 phpjm 就大了不少,手工来做还原就比较费劲,可以使用 nikic/php-parser 对文件做解析,把其中所有变量从不可见字符给换成可见字符串,再手动对代码做一些修复和替换使其可读性更高,方便还原解密逻辑,对函数和符号重命名的 Visitor 如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| class VariableVisitor extends NodeVisitorAbstract
{
public function leaveNode(Node $node) {
global $varCount, $funcCount, $maps;
if ($node instanceof Expr\Variable) {
$varName = is_string($node->name) ? $node->name : $node->name->name;
$varName = md5($varName);
if ($varName && !array_key_exists($varName, $maps)) {
$maps[$varName] = 'var' . $varCount++;
}
$node->name = $maps[$varName];
}
if ($node instanceof Node\Stmt\Function_) {
$funcName = $node->name->name;
$funcName = md5($funcName);
if ($funcName && !array_key_exists($funcName, $maps)) {
$maps[$funcName] = 'func' . $funcCount++;
}
$node->name = $maps[$funcName];
}
}
}
|
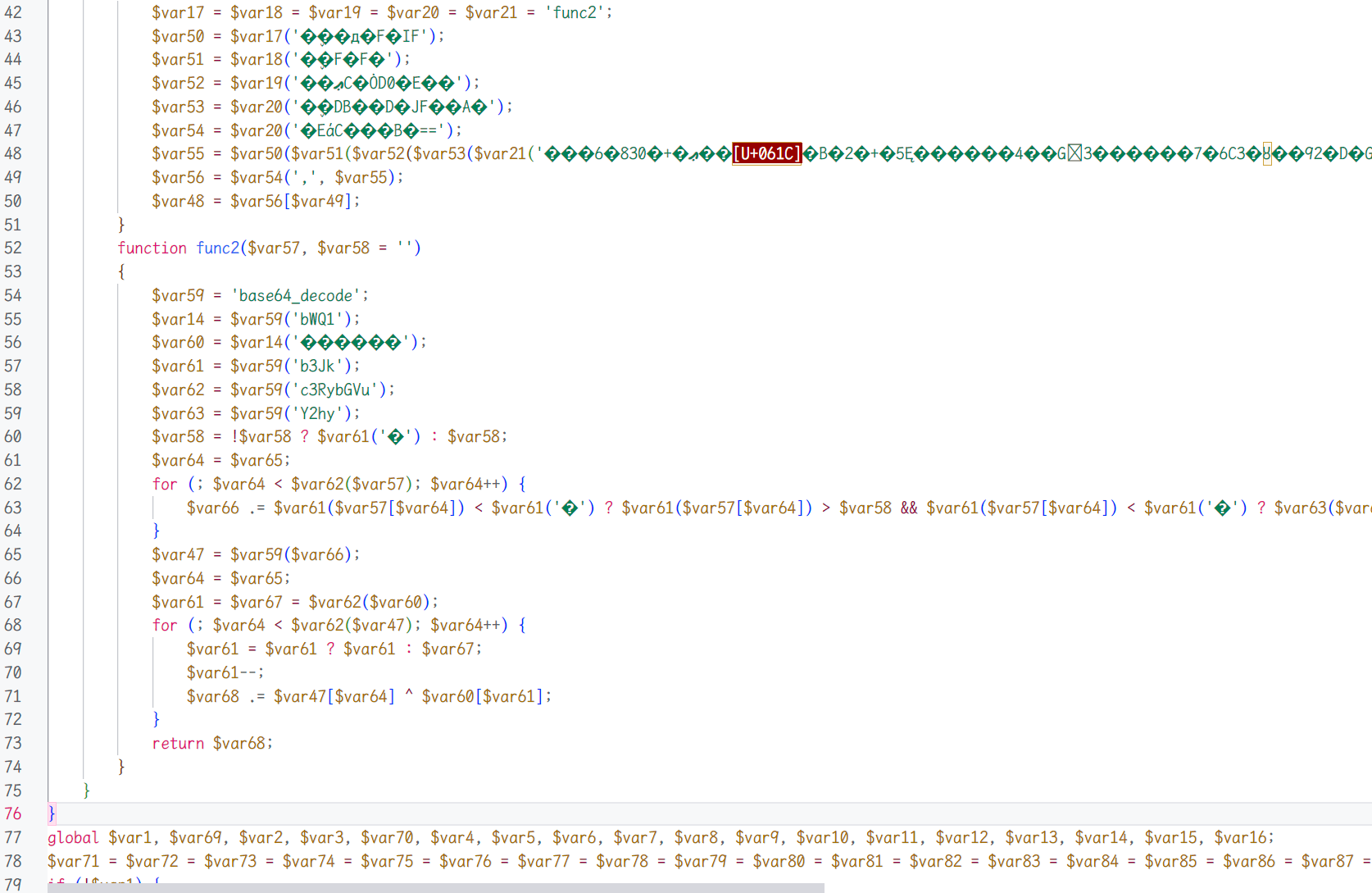
在大致恢复符号后可以发现一共有三个函数,被重新命名成了func0,func1,func2,由于只有func2中有一个可见字符的函数:base64_decode 并且之后有一堆明显的调用,那么从恢复这个函数开始,手动将其解码再重新赋值,恢复完成之后会发现其实这是一个核心的解密函数,func2恢复对比如下
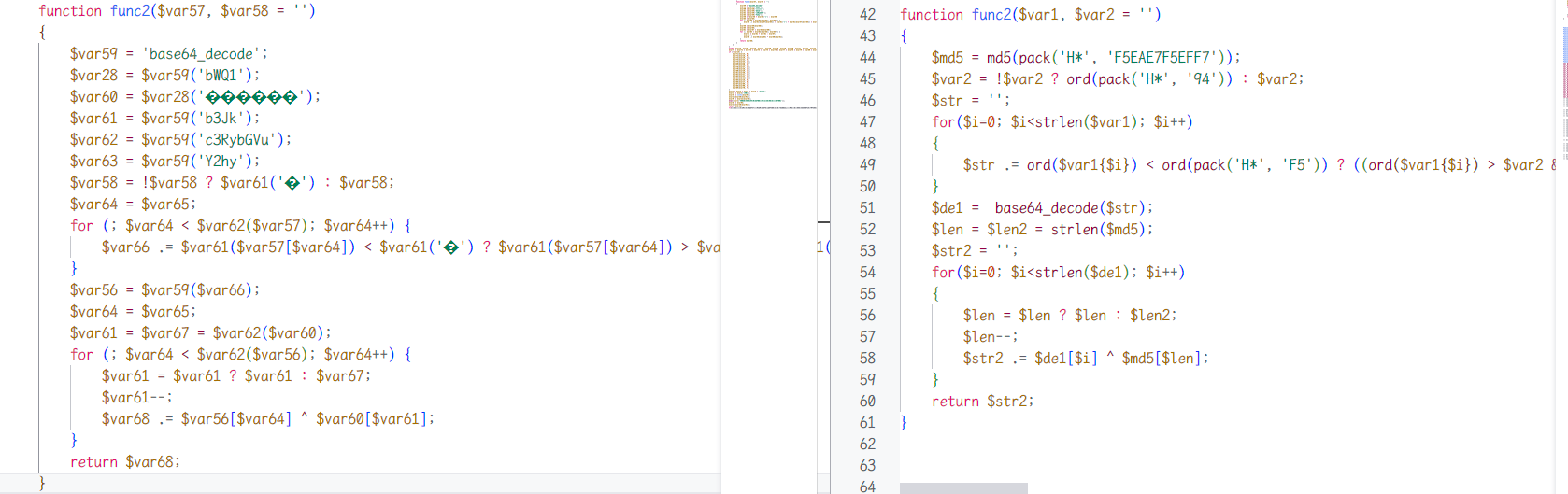
如法炮制恢复出func1,可以发现就是一个比较简单的解码操作
1
2
3
4
5
6
| function func1(&$var1, $var2) {
$enc = func2(pack('H*', 'A6CAE0B236F23833DEA29A2B9C30E2DCD89CEA42AE32EE2BE635C4989AD2D8C2E8EE34C4CA47C29A33A0AAC8C8DAE0B037D8364333E2C8A2C4EC3932F244E04730F4A6CEA2D2E2B238C439F4EE9EB234DCCE9C30493338E8AA474396A6969847D898CC309CE44A379AC6C4A64235D6AEAEDC3749DCF4A246C630383944DEACF2A04AB22B2F2BA2A4F0333098C6B0364632E8E0A6E62FEAC637ECD849AC4546CC30A647C2F0A039C239C6A8DEC4DC35D0CCC4E24748A241AEE02B9C46E8DADADAF444A6CC'));
$res = str_rot13(strrev(gzuncompress(stripslashes($enc))));
$s = explode(',', $res);
$var1 = $s[$var2];
}
|
对其进行解码后dump出来发现其实就是函数符号表,供var1这一堆很长的全局变量使用

最后解到func0,会发现这就是最终解出原始代码的函数,其中有一堆校验防止用户破解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| function func0($var1) {
php_sapi_name() == 'cli' ? die() : ''; // 防止在cli下运行
$content = file_get_contents(__FILE__);
// 同样防止在cli下运行,这里可能是怕直接hook了php_sapi_name
if(!isset($_SERVER['HTTP_HOST']) && !isset($_SERVER['SEREVER_ADDR']) && !isset($_SERVER['REMOTE_ADDR'])) {
die();
}
$time = microtime(true) * 1000;
// 防止eval hook,断点时间超1秒就退出
eval("");
if (microtime(true) * 1000 - $time > 100) {
die();
}
eval("if(strpos(__FILE__, 'nirpnqsz') !== 0){$exitfunc();}");
!strpos(func2(substr($content, func2(getHexStr('4841A4A2')), func2(pack('H*', '4841453D'))), md5(substr($content, func2(), func2())))) ? undefined() : undefined();
$start = func2(pack('H*', '484146A6ACA23D3D'));
$end = func2(pack('H*', '4841A4A8'));
// 还原的核心代码,其实就是取了?>后那一堆乱码
$content = str_rot13(@gzuncompress(func2(substr($content, $start, $end))));
return $content;
}
|
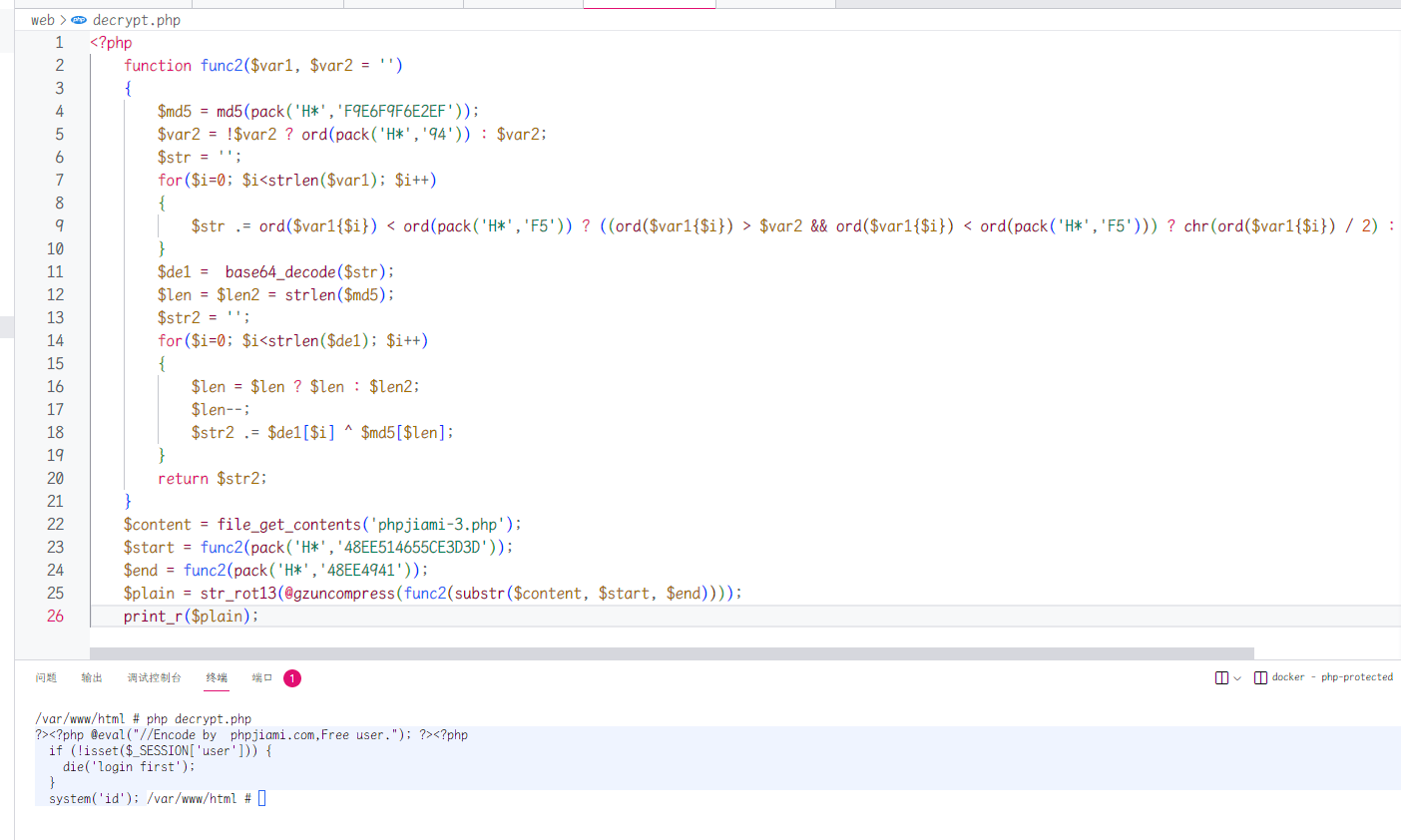
将还原的核心代码取出来 str_rot13(@gzuncompress(func2(substr($content, $start, $end)))); 对着加密后的文件做一下调用,就可以还原出加密前的代码了
扩展加密(源码混淆)
当加密到了这一步,方式开始有所变化,比如需要用户手动编译启用一个php扩展,使用扩展提供的工具对文件进行一次对应的加密,这样在web目录中的文件几乎全是乱码,任何可见符号都看不到,但究其本质上来讲,这种加密其实和上述的两种加密没有任何区别,只不过增加了一点扩展逆向难度而已,下面同样使用两种市面上常见的扩展作为例子
php-beast
项目地址:https://github.com/liexusong/php-beast
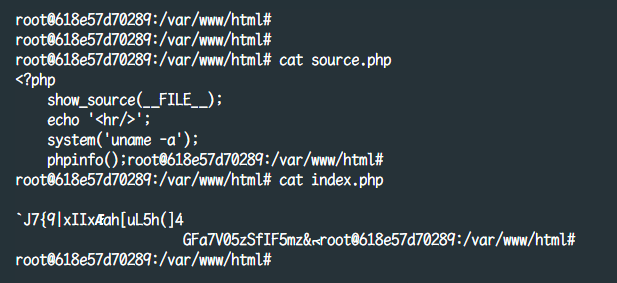
使用这个扩展对文件进行处理后,整个文件将变成完全不可读的状态,在非默认情况下脱离了扩展本身其实也很难还原,加密前后对比如下
直接看他如何hook的 compile_file
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| zend_op_array *__fastcall cgi_compile_file(zend_file_handle *h, int type)
{
const char *filename; // rdi
FILE *v4; // rax
FILE *v5; // rbp
int v6; // eax
int v7; // eax
zend_stream_type v8; // eax
file_handler *v9; // rax
int v10; // edx
int v11; // r13d
beast_free_buf_t *free; // rax
beast_ops *ops; // [rsp+8h] [rbp-40h] BYREF
char *buf; // [rsp+10h] [rbp-38h] BYREF
int free_buffer; // [rsp+18h] [rbp-30h] BYREF
int size[3]; // [rsp+1Ch] [rbp-2Ch] BYREF
filename = h->filename;
free_buffer = 0;
ops = 0LL;
v4 = fopen(filename, "rb");
v5 = v4;
if ( !v4 )
goto final;
v6 = fileno(v4);
v7 = decrypt_file(h->filename, v6, &buf, size, &free_buffer, &ops);
// ...
return old_compile_file(h, type);
}
|
在打开文件后调用了自己实现的 decrypt_file ,之后做了一系列操作重新将解密后的内容扔给了 old_compile_file 继续正常的编译执行操作,那么主要关注到这个 decrypt_file,看看是如何做的解密
首先经由beast混淆过的文件会有一个文件头特征,默认情况下将会是:0xe8, 0x16, 0xa4, 0x0c, 0xf2, 0xb2, 0x60, 0xee ,代码中会检查这个文件头来判断是否是加密文件。用户可以在编译之前修改 header.c 来替换掉这个值,所以这个特征并不是固定的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| .data:000000000000E668 public encrypt_file_header_sign
.data:000000000000E668 ; char encrypt_file_header_sign[8]
.data:000000000000E668 encrypt_file_header_sign db 0E8h, 16h, 0A4h, 0Ch, 0F2h, 0B2h, 60h, 0EEh
.data:000000000000E668 ; DATA XREF: LOAD:0000000000000EF0↑o
.data:000000000000E668 ; .got:encrypt_file_header_sign_ptr↑o
.data:000000000000E660 public encrypt_file_header_length
.data:000000000000E660 ; int encrypt_file_header_length
.data:000000000000E660 encrypt_file_header_length dd 8 ; DATA XREF: LOAD:00000000000010A0↑o
.data:000000000000E660 ; .got:encrypt_file_header_length_ptr↑o
if ( memcmp(header, encrypt_file_header_sign, encrypt_file_header_length) )
{
if ( log_normal_file )
{
beast_write_log(beast_log_error, "File `%s' isn't a encrypted file", filename);
return -1;
}
return -1;
}
|
在判断文件头符合之后,会继续从文件头中取出三个信息,文件大小、有效日期与加密方式,其中最重要的就是加密方式这个值(三个值都需要转为大端序)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| v16 = *(_DWORD *)&header[encrypt_file_header_length];
v17 = *(_DWORD *)&header[encrypt_file_header_length + 4];
v18 = *(_DWORD *)&header[encrypt_file_header_length + 8];
v42 = 4386;
v19 = (v16 << 24) | ((int)(v16 & 0xFF0000) >> 8) | ((v16 & 0xFF00) << 8) | HIBYTE(v16);
v20 = (v17 << 24) | ((int)(v17 & 0xFF0000) >> 8) | ((v17 & 0xFF00) << 8) | HIBYTE(v17);
v21 = (v18 << 24) | ((int)(v18 & 0xFF0000) >> 8) | ((v18 & 0xFF00) << 8) | HIBYTE(v18);
if ( beast_max_filesize > 0 && v19 > beast_max_filesize )
{
beast_write_log(
beast_log_error,
"File size `%d' out of max size `%d'",
(unsigned int)v19,
(unsigned int)beast_max_filesize);
return -1;
}
if ( v20 > 0 && v20 < beast_now_time )
{
beast_write_log(beast_log_error, "File `%s' was expired", filename);
return -2;
}
v31 = chk;
encrypt_algo = beast_get_encrypt_algo(v21);
|
将代码所示具体到文件中,就可以看到文件头中关于这四个信息的情况,分别为文件头标志、文件大小、有效日期以及加密方式
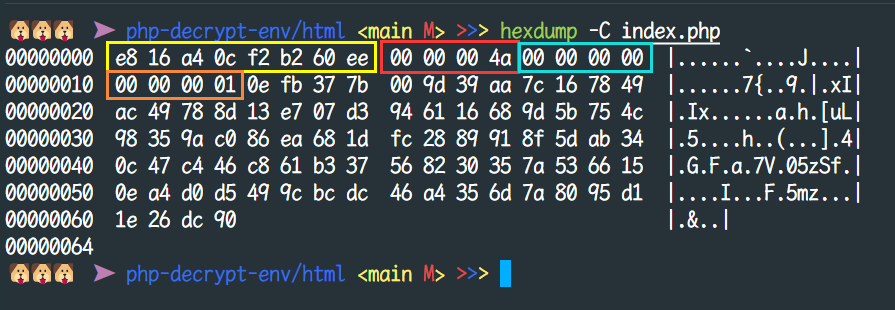
现在知道了加密方式为 1,那么继续跟入看看这个数字代指什么方式的混淆
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| beast_ops *__fastcall beast_get_encrypt_algo(int type)
{
return beast_get_encrypt_algo(type);
}
beast_ops *__fastcall beast_get_encrypt_algo(int type)
{
unsigned int v1; // edi
v1 = type - 1;
if ( v1 > 3 )
return ops_handler_list[0];
else
return ops_handler_list[v1];
}
.data:000000000020C620 public ops_handler_list
.data:000000000020C620 ; beast_ops *ops_handler_list[4]
.data:000000000020C620 ops_handler_list dq offset des_handler_ops, offset aes_handler_ops, offset base64_handler_ops
.data:000000000020C620 ; DATA XREF: LOAD:0000000000001AE8↑o
.data:000000000020C620 ; .got:ops_handler_list_ptr↑o
.data:000000000020C638 dq offset dword_0
|
这里就能看到beast提供的三种代码混淆方式:DES、AES、BASE64,默认DES,这里我们的值为1,可得当前文件使用的混淆方式是DES,那么接下来的事情就比较简单了,在对应的 decrypt_handler 中找到对应的key,然后使用python简单写个解密脚本即可(这里的key同样是可以被修改掉的)
1
2
3
4
| .data:000000000000E5A8 ; char key_0[8]
.data:000000000000E5A8 key_0 db 1, 1Fh, 1, 1Fh, 1, 0Eh, 1, 0Eh
.data:000000000000E5A8 ; DATA XREF: des_encrypt_handler+89↑o
.data:000000000000E5A8 ; des_decrypt_handler+50↑o
|
针对加密后文件进行解密的操作如下所示(AES与BASE64同理)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| from Crypto.Cipher import DES
from Crypto.Util.Padding import pad
ECB_KEY = b'\x01\x1F\x01\x1F\x01\x0E\x01\x0E'
HEAD_LENGTH = 8
ENCRYPT_TYPES = [ 'DES', "AES" , 'BASE64']
def des_decrypt(ciphertext):
cipher = DES.new(ECB_KEY, DES.MODE_ECB)
plaintext = cipher.decrypt(ciphertext)
return plaintext.decode('utf-8', errors='ignore')
with open('./index.php', 'rb') as f:
content = f.read()
head_sign = content[:HEAD_LENGTH]
file_size = int.from_bytes(content[HEAD_LENGTH: HEAD_LENGTH + 4], 'big')
encrypt_type = int.from_bytes(content[HEAD_LENGTH + (4 * 2): HEAD_LENGTH + (4 * 3)], 'big')
print('[+] file size: %dB' % file_size)
print('[+] encrypt type: %s' % ENCRYPT_TYPES[encrypt_type - 1])
enc_filedata = content[HEAD_LENGTH + (4 * 3):]
padded_content = pad(enc_filedata, DES.block_size)
plaintext = des_decrypt(padded_content)
print(plaintext)
|
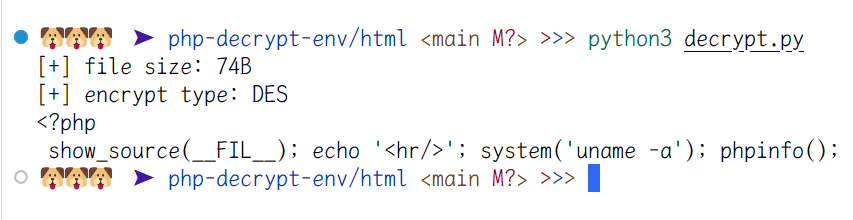
PHP Screw
项目地址:https://github.com/Luavis/php-screw
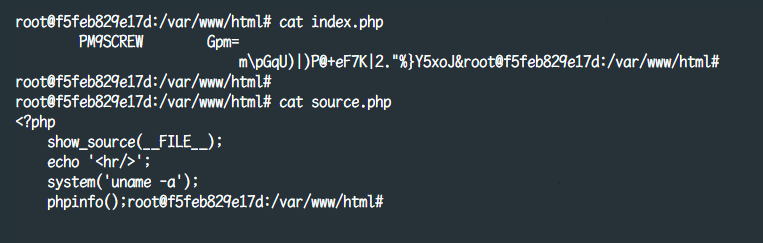
和php-beast一样,screw同样是通过hook了 compile_file 来做的混淆操作,原理上来讲大同小异,混淆算法的区别而已,加密前后代码对比如下所示
在screw中,有一个初始化函数 zm_startup_php_screw 用来替换函数指针
1
2
3
4
5
6
| int __fastcall zm_startup_php_screw(int type, int module_number)
{
org_compile_file = (zend_op_array *(*)(zend_file_handle *, int))zend_compile_file;
zend_compile_file = pm9screw_compile_file;
return 0;
}
|
所以我们主要看到hook的函数 pm9screw_compile_file ,这个函数本身比较短
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| zend_op_array *__fastcall pm9screw_compile_file(zend_file_handle *file_handle, int type)
{
FILE *v3; // rax
FILE *v4; // rbp
zend_stream_type v5; // eax
FILE *v6; // rax
const char *filename; // rdi
const char *active_function_name; // rax
char buf[11]; // [rsp+5h] [rbp-53h] BYREF
char fname[32]; // [rsp+10h] [rbp-48h] BYREF
memset(fname, 0, sizeof(fname));
if ( (unsigned __int8)zend_is_executing() )
{
if ( get_active_function_name() )
{
active_function_name = (const char *)get_active_function_name();
strncpy(fname, active_function_name, 0x1EuLL);
if ( fname[0] )
{
if ( !strcasecmp(fname, "show_source") || !strcasecmp(fname, "highlight_file") )
return 0LL;
}
}
}
v3 = fopen(file_handle->filename, "r");
v4 = v3;
if ( !v3 )
return org_compile_file(file_handle, type);
fread(buf, 0xAuLL, 1uLL, v3);
if ( !memcmp(buf, "\tPM9SCREW\t", 0xAuLL) )
{
v5 = file_handle->type;
if ( file_handle->type == ZEND_HANDLE_FP )
{
fclose(file_handle->handle.fp);
v5 = file_handle->type;
}
if ( v5 == ZEND_HANDLE_FD )
close(file_handle->handle.fd);
v6 = pm9screw_ext_fopen(v4);
filename = file_handle->filename;
file_handle->handle.fp = v6;
file_handle->type = ZEND_HANDLE_FP;
file_handle->opened_path = (char *)expand_filepath(filename, 0LL);
return org_compile_file(file_handle, type);
}
fclose(v4);
return org_compile_file(file_handle, type);
}
|
在这里我们发现,使用screw做保护方案的代码,默认情况下同样会又有一个明显的文件特征 \tPM9SCREW\t (这个特征值可以在php_screw.h文件中被修改掉)

如果存在这个文件头,那么才会被当做已混淆的代码,进入解密流程,否则就直接使用原始 zend_compile_file 进行编译执行,所以想要解密文件,继续跟入 pm9screw_ext_fopen 看看究竟是如何处理,这个函数同样不大
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| FILE *__fastcall pm9screw_ext_fopen(FILE *fp)
{
int v1; // eax
int st_size; // ebp
int v3; // r12d
char *v4; // rbx
char *v5; // rsi
int v6; // ecx
char *v7; // r12
FILE *v8; // rbp
int newdatalen; // [rsp+Ch] [rbp-BCh] BYREF
stat stat_buf; // [rsp+10h] [rbp-B8h] BYREF
v1 = fileno(fp);
__fxstat(1, v1, &stat_buf);
st_size = stat_buf.st_size;
v3 = LODWORD(stat_buf.st_size) - 10;
v4 = (char *)malloc(LODWORD(stat_buf.st_size) - 10);
fread(v4, v3, 1uLL, fp);
fclose(fp);
if ( v3 > 0 )
{
v5 = v4;
do
{
v6 = st_size - 10;
--st_size;
++v5;
*(v5 - 1) = LOBYTE(pm9screw_mycryptkey[v6 % 5]) ^ ~*(v5 - 1);
}
while ( st_size != 10 );
}
v7 = zdecode(v4, v3, &newdatalen);
v8 = tmpfile();
fwrite(v7, newdatalen, 1uLL, v8);
free(v4);
free(v7);
rewind(v8);
return v8;
}
|
加密原理就是非常简单的xor而已,那么我们需要关心的主要就是这个 pm9screw_mycryptkey
1
2
3
4
5
| .data:0000000000202128 public pm9screw_mycryptkey
.data:0000000000202128 ; __int16 pm9screw_mycryptkey[5]
.data:0000000000202128 pm9screw_mycryptkey dw 2B90h, 170h, 0C0h, 501h, 3Eh
.data:0000000000202128 ; DATA XREF: LOAD:0000000000000600↑o
.data:0000000000202128 ; .got:pm9screw_mycryptkey_ptr↑o
|
在获取了对应的key后,就可以使用python对照着写一个解密脚本,使用效果如下
1
2
3
4
5
6
7
8
9
10
| def decrypt_file(content):
file_size = len(content)
compress_data = b''
if file_size > 0:
tmp_data = bytearray(content)
for i in range(file_size):
tmp_data[i] = ctypes.c_ubyte(screw_key[file_size % 5] ^ ~tmp_data[i]).value
file_size -= 1
compress_data = bytes(tmp_data)
return zlib.decompress(compress_data)
|

通用还原方法
hook compile_string
上面这几种加密,其实只是对源码整体给压缩编码一下套层壳,实际上并没有改动代码本身,类似无扩展中 eval(string) 这样的加密,直接hook住 compile_string 就可以解开,这类实现网上已经非常多,比如使用如下的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| int c, len;
char *copy;
if (Z_TYPE_P(source_string) != IS_STRING) {
return orig_compile_string(source_string, filename TSRMLS_CC);
}
len = Z_STRLEN_P(source_string);
copy = estrndup(Z_STRVAL_P(source_string), len);
if (len > strlen(copy)) {
for (c=0; c<len; c++) if (copy[c] == 0) copy[c] == '?';
}
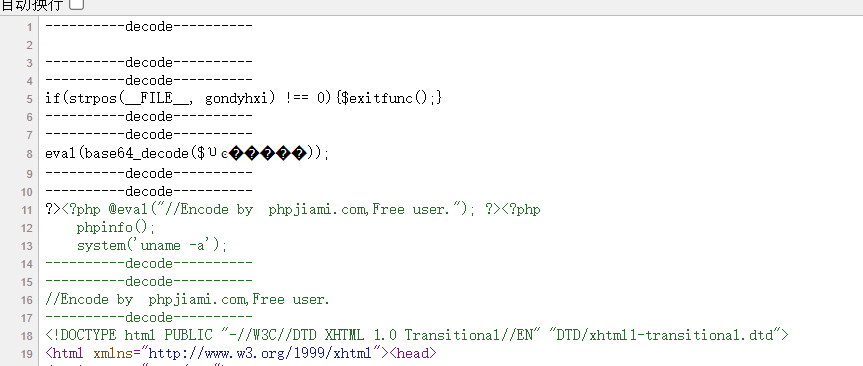
php_printf("----------decode----------\n");
php_printf("%s\n", copy);
php_printf("----------decode----------\n");
|
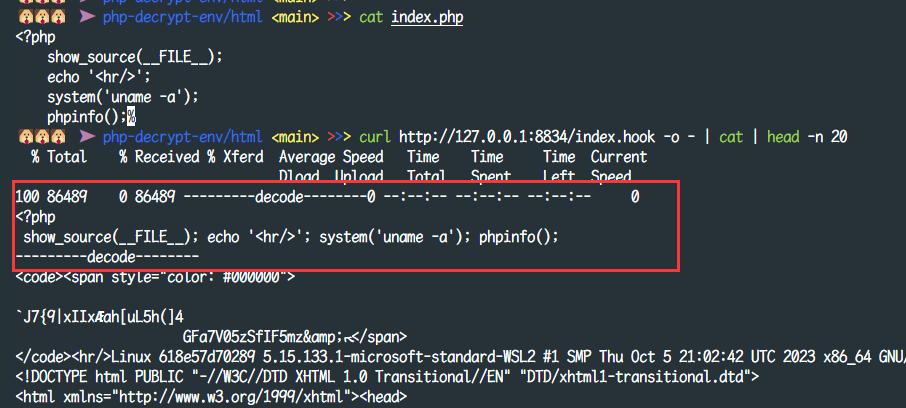
编译并启用扩展后访问目标文件,针对phpjiami的解密效果如下所示
hook compile_file
但是这种方法对于 php-beast 对整个文件做操作的加密显然不奏效,那么针对这种加密需要hook另一个地方,也就是 compile_file
不同php版本下的file_handle结构是不相同的,需要根据不同的版本做调整
当前PHP版本(7.3.33) file_handle 结构如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| typedef struct _zend_file_handle {
union {
int fd;
FILE *fp;
zend_stream stream;
} handle;
const char *filename;
zend_string *opened_path;
zend_stream_type type;
zend_bool free_filename;
} zend_file_handle;
// 我们可以使用这个函数,将内容写到buf中
ZEND_API int zend_stream_fixup(zend_file_handle *file_handle, char **buf, size_t *len);
|
在 vld_compile_file 中,添加一段代码
1
2
3
4
5
6
7
8
9
10
| // 注意,需要在原始compile_file之后调用,否则文件内容仍然是加密后的
op_array = old_compile_file(file_handle, type);
char *buf;
size_t size;
if (zend_stream_fixup(file_handle, &buf, &size) == SUCCESS) {
php_printf("---------decode--------\n");
php_printf("%s\n", buf);
php_printf("---------decode--------\n");
}
|
针对 php-beast 的解密效果如下
扩展加密(opcode)
当混淆到了这个时候,扩展接管了编译这个过程,直接拿出完整的opcode交到zend引擎执行,所以我们已经没有办法再使用上述流程通过hook compile_file 的方式来拿到加密之前的文件内容,能使用通用方式做到的最后一步,就是取到这个opcode,然后通过各种方式对这个opcode进行还原,下面使用 SourceGuardian 作为例子
SourceGuardian11.4
使用SourceGuardian11.4加密后的文件与原始文件对比
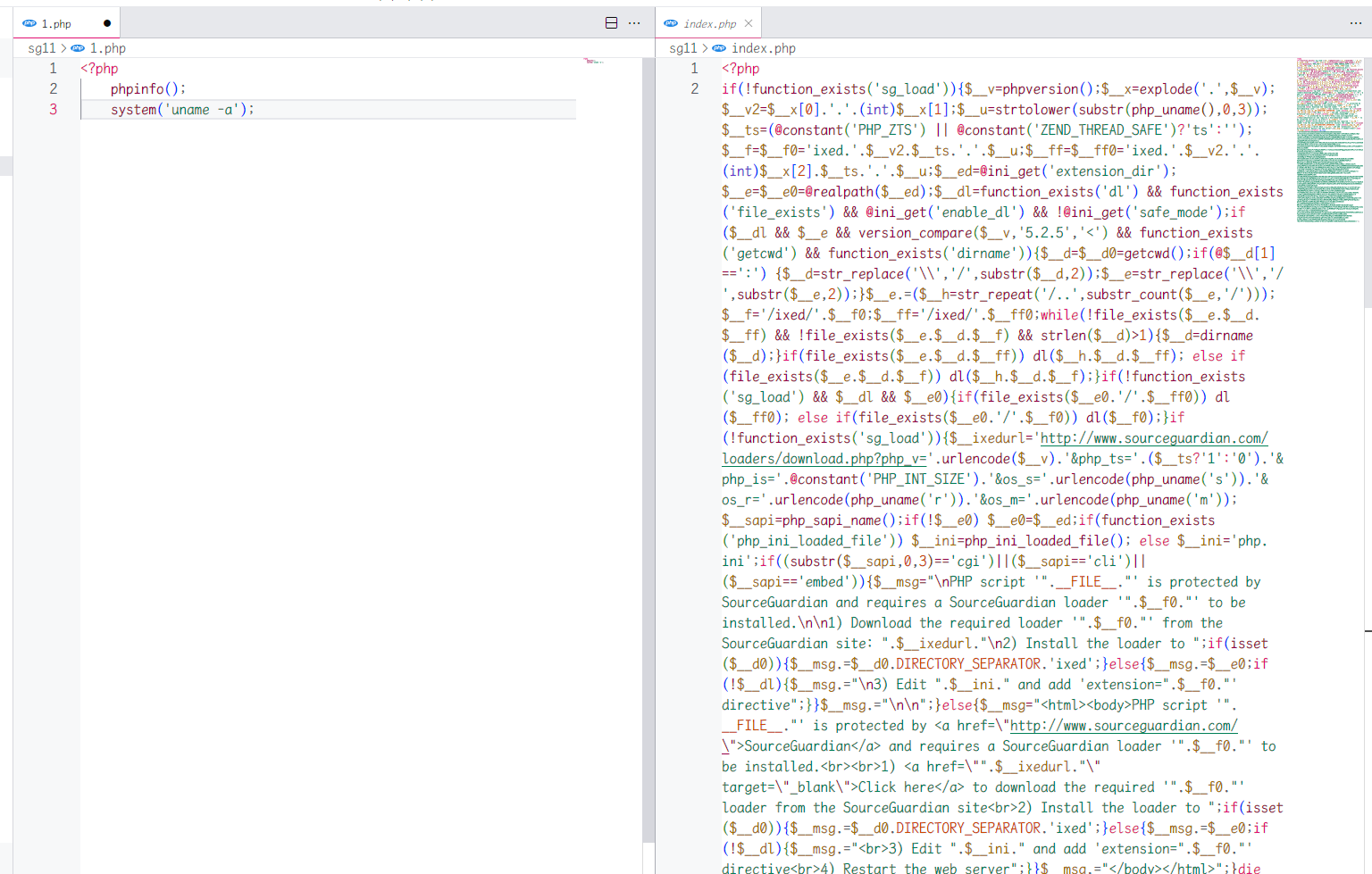
由于SourceGuardian并不是通过hook compile_file、 compile_string 来实现源码加密的,所以我们需要找到一种新的办法,首先来看一看loader的处理流程,可以知道他肯定会处理一个sg_load的函数,当前以ixed.7.3.lin为例,将sg_load作为入口分析一下究竟做了什么操作
1
2
3
4
5
6
7
8
| .data:000000000021A7E0 off_21A7E0 dq offset aSgLoad ; DATA XREF: .data:000000000021A988↓o
.data:000000000021A7E0 ; "sg_load"
.data:000000000021A7E8 dq offset sub_9560
__int64 __fastcall sub_9560(__int64 a1, __int64 a2)
{
return sub_6880(a1, a2);
}
|
在函数 sub_6880 中确实看到了处理的流程
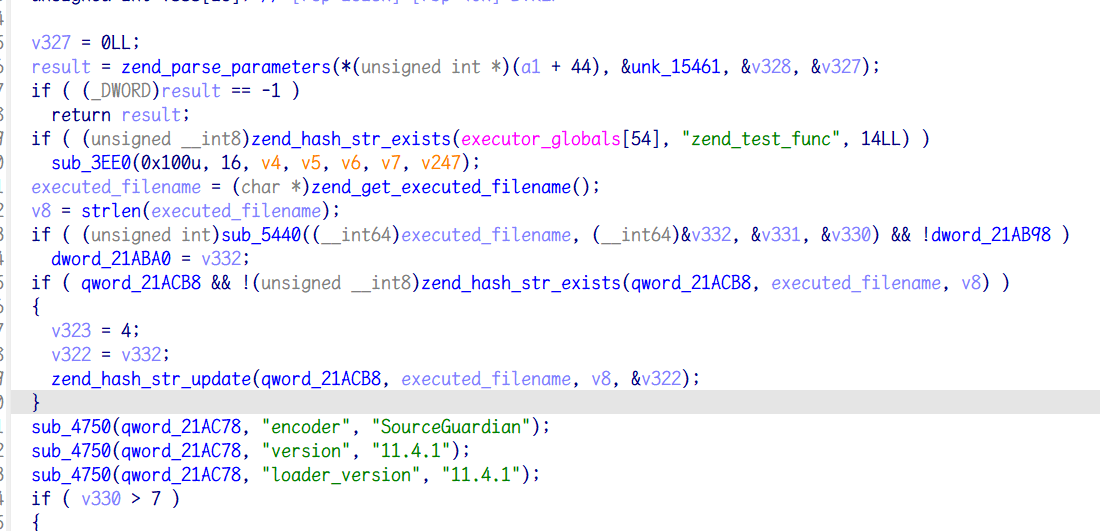
由于整个函数去了符号而且特别长,逆向难度稍大,但是不用管前面的流程,直接拉到函数末尾可以看到一个比较关键的地方
1
2
3
4
5
6
7
8
9
| if ( v304 && !dword_21AD24 )
{
executed_scope = zend_get_executed_scope();
dword_21AB98 = 1;
v304[2] = executed_scope;
zend_execute((__int64)v304, a2);
destroy_op_array(v304);
return _efree(v304);
}
|
zend_execute(v304, a2) 以及 destroy_op_array(v304) ,也就是说 v304 这个变量是一个 zend_op_array 类型的值,所以理论上如果我们可以获取到 v304 这个值,那么也就可以通过阅读opcode来还原代码,继续看看php中关于 zend_execute 的处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| # Zend/zend_vm_execute.h
ZEND_API void zend_execute(zend_op_array *op_array, zval *return_value)
{
zend_execute_data *execute_data;
void *object_or_called_scope;
uint32_t call_info;
if (EG(exception) != NULL) {
return;
}
object_or_called_scope = zend_get_this_object(EG(current_execute_data));
if (EXPECTED(!object_or_called_scope)) {
object_or_called_scope = zend_get_called_scope(EG(current_execute_data));
call_info = ZEND_CALL_TOP_CODE | ZEND_CALL_HAS_SYMBOL_TABLE;
} else {
call_info = ZEND_CALL_TOP_CODE | ZEND_CALL_HAS_SYMBOL_TABLE | ZEND_CALL_HAS_THIS;
}
# 分配zend_execute_data
execute_data = zend_vm_stack_push_call_frame(call_info, (zend_function*)op_array, 0, object_or_called_scope);
# 设置符号表
if (EG(current_execute_data)) {
execute_data->symbol_table = zend_rebuild_symbol_table();
} else {
execute_data->symbol_table = &EG(symbol_table);
}
EX(prev_execute_data) = EG(current_execute_data); // execute_data->prev_execute_data = EG(current_execute_data)
i_init_code_execute_data(execute_data, op_array, return_value); // 初始化execute_data
ZEND_OBSERVER_FCALL_BEGIN(execute_data);
zend_execute_ex(execute_data); // 执行opcode
/* Observer end handlers are called from ZEND_RETURN */
zend_vm_stack_free_call_frame(execute_data); //释放execute_data,销毁所有变量
}
|
在这里面使用 op_array 做了一些初始化 execute_data 的操作,最终调用 zend_execute_ex 这个函数,所以我们可以直接hook住 zend_execute_ex 这个函数,在这其中来对 execute_data 这个值做一下dump操作就能获取到目标opcode,execute_data 结构如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| struct _zend_execute_data {
const zend_op *opline; /* executed opline */
zend_execute_data *call; /* current call */
zval *return_value;
zend_function *func; /* executed function */
zval This; /* this + call_info + num_args */
zend_execute_data *prev_execute_data;
zend_array *symbol_table;
void **run_time_cache; /* cache op_array->run_time_cache */
zend_array *extra_named_params;
};
union _zend_function {
zend_uchar type; /* MUST be the first element of this struct! */
uint32_t quick_arg_flags;
struct {
zend_uchar type; /* never used */
zend_uchar arg_flags[3]; /* bitset of arg_info.pass_by_reference */
uint32_t fn_flags;
zend_string *function_name;
zend_class_entry *scope;
zend_function *prototype;
uint32_t num_args;
uint32_t required_num_args;
zend_arg_info *arg_info; /* index -1 represents the return value info, if any */
HashTable *attributes;
} common;
zend_op_array op_array;
zend_internal_function internal_function;
};
|
那么可以通过dump execute_data->func->op_array 来获取到对应的opcode,但是 zend_op_array 这个结构比较大而且很复杂,如果自己来写解析会很麻烦,不过已经有人已经做过这个工作,可以直接在这个基础上进行修改,比如 VLD https://github.com/derickr/vld
修改vld
在vld中,作者本身就已经hook了两个函数 compile_file 和 compile_string,留下了一个没有代码块的空函数 vld_execute_ex 也就是目标hook函数,在初始化过程中,vld开始hook三个函数,这里需要注意的是,只有当 active=1 且 execute=0 的时候,我们需要hook的 zend_execute_ex 才会被替换成 vld_execute_ex
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| PHP_RINIT_FUNCTION(vld)
{
old_compile_file = zend_compile_file;
old_compile_string = zend_compile_string;
old_execute_ex = zend_execute_ex;
if (VLD_G(active)) {
zend_compile_file = vld_compile_file;
zend_compile_string = vld_compile_string;
if (!VLD_G(execute)) {
zend_execute_ex = vld_execute_ex;
}
}
// ...
|
直接在 vld_execute_ex 中来编写一下dump opcode的代码,这里可以直接将原本 compile_file/string 中的用法拿过来就好,有一点需要注意的是调用内部函数、用户定义函数、回调等情况,也会调用到 execute_ex,如果直接在这里面不加任何条件在真实环境中使用,就会因为各种调用而跑飞掉,所以我们需要在这里面加一些限制,让他只输出我们目标文件的opcode
但是又不能进入函数直接dump就返回,因为第一次调用到 execute_ex 一定是 sg_load ,这个时候dump出来仍然是不可读的opcode,那么可以在这里加一个标志位做一次判断,看是否第一次执行,如果是的话那么让他正常走向原始 execute_ex,如果已经执行过一次,那么这时的opcode就是代码本身,取出 execute_data->func->op_array 然后使用 vld_dump_oparray dump出来,代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
| bool flag = false;
static void vld_execute_ex(zend_execute_data *execute_data)
{
// nothing to do
if (flag) {
vld_dump_oparray(&execute_data->func->op_array TSRMLS_CC);
zend_hash_apply_with_argument(CG(function_table) TSRMLS_CC, (apply_func_args_t)VLD_WRAP_PHP7(vld_dump_fe), 0);
zend_hash_apply(CG(class_table), (apply_func_t)VLD_WRAP_PHP7(vld_dump_cle) TSRMLS_CC);
return;
}
flag = true;
old_execute_ex(execute_data);
}
|
至此,我们就可以实现在运行时将代码执行的真实opcode给dump出来,如下所示
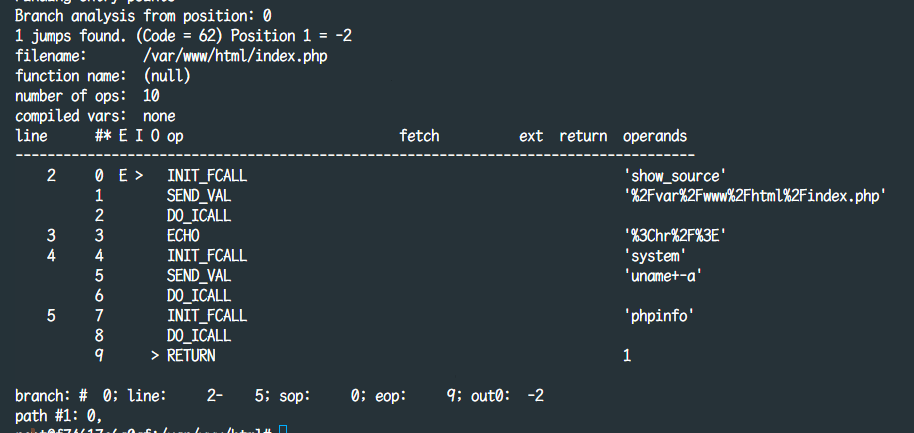
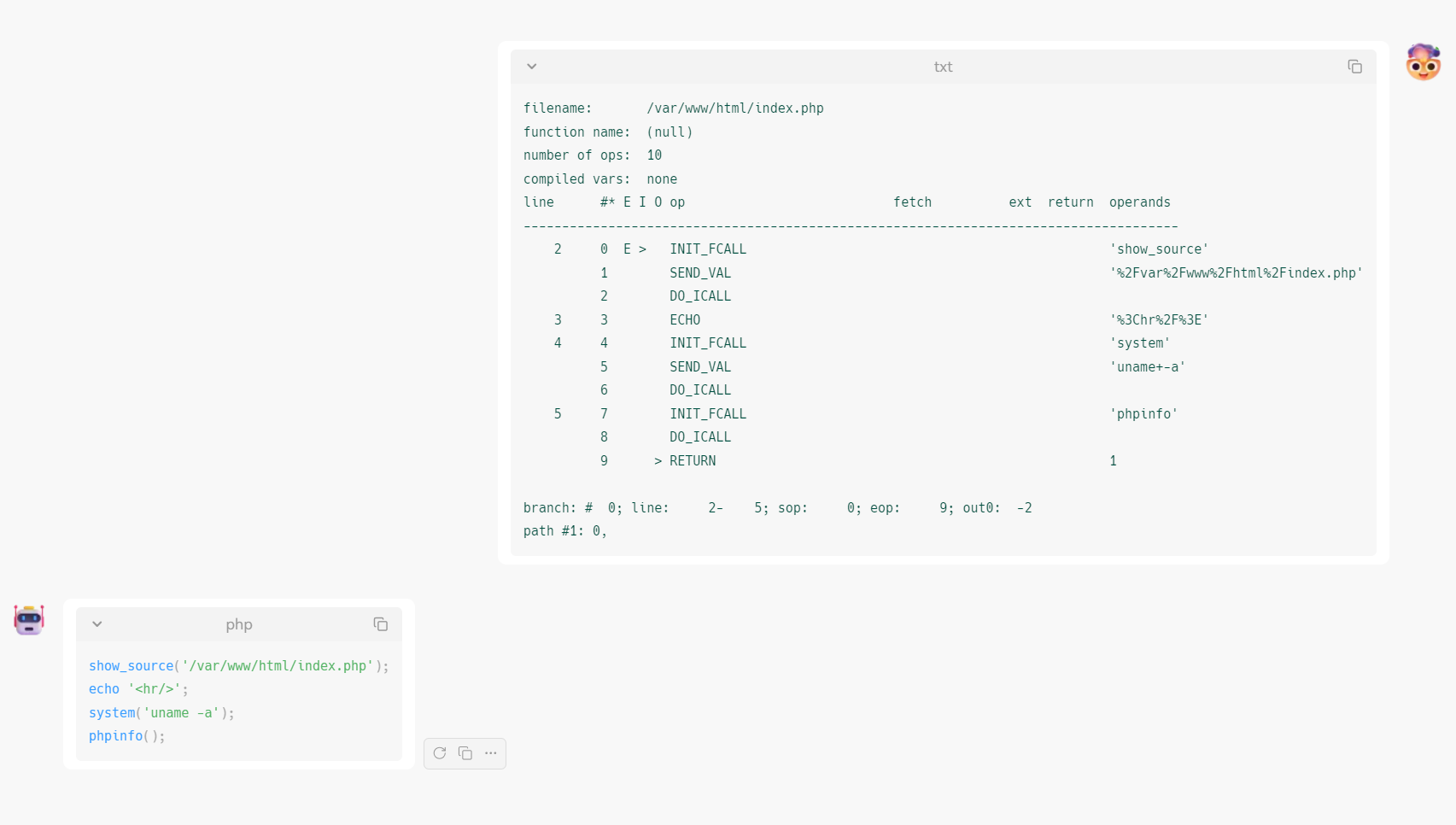
之后就需要将dump出来的opcode转换为原始php代码,所幸php中的opcode可读性很强,如果会写php,哪怕从没见过这些指令也能还原个七七八八。但是这个工作如果纯人工来做会比较费时费力,现在或许可以直接尝试使用gpt来帮助还原一下,比如当前这个文件的完整opcode如下,编写对应的prompt之后让gpt帮忙翻译一下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| filename: /var/www/html/index.php
function name: (null)
number of ops: 10
compiled vars: none
line #* E I O op fetch ext return operands
-------------------------------------------------------------------------------------
2 0 E > INIT_FCALL 'show_source'
1 SEND_VAL '%2Fvar%2Fwww%2Fhtml%2Findex.php'
2 DO_ICALL
3 3 ECHO '%3Chr%2F%3E'
4 4 INIT_FCALL 'system'
5 SEND_VAL 'uname+-a'
6 DO_ICALL
5 7 INIT_FCALL 'phpinfo'
8 DO_ICALL
9 > RETURN 1
branch: # 0; line: 2- 5; sop: 0; eop: 9; out0: -2
path #1: 0,
|
gpt翻译结果如下,对于代码量不大且不是过分复杂的opcode相对来说能省去不少工作